-
《人工智能》目录
-
前言
-
数据中心
-
理论知识
-
基本安装
-
基本知识
-
Transformer
-
脉冲神经网络 (SNN)
-
数据处理
-
声音处理
- FunASR:阿里的语音识别
- Kaldi:ASR,语音识别,可以训练声学模型
- 星辰语音识别开源大模型:中国电信,【超多方言】ASR
- 最难方言温州话被攻克!中国电信语音大模型支持30种方言
- 播放音频文件
- 让 Python 来帮你朗读网页吧
- 从零开始搭建一个语音对话机器人
- Seed-TTS:字节发布高性能高逼真语音合成框架
- ChatTTS:语音合成
- edge-tts:语音合成,调用的微软edge的在线语音合成服务
- pyttsx3:语音转换
- python实现TTS离线语音合成
- StyleTTS2:one-shot语音风格迁移和逼真语音转换的论文阅读和代码实战
- Matcha-TTS:语音合成,
- Bailing-TTS:巨人网络支持普通话和方言混说的TTS大模型
-
图像处理
-
视频处理
-
文字处理
-
多模处理
-
动态记忆和自我反思
-
论文精选
-
大模型LLM
-
AIAgent
- 新一代AI模型Claude 3:有大学生智商,全面超越GPT-4
- FastChat——一个用于训练、部署和评估基于大型语言模型的聊天机器人的开放平台
- 谷歌DeepMind推出新一代药物研发AI模型AlphaFold 3
- LangChain-Chatchat (原 Langchain-ChatGLM)
- MaxKB本地私有大模型部署
- YOLO v10视觉目标检测算法本地端部署
- Fay数字人框架 助理版
- 百度开源 / Senta - 情感分析旨
- Moshi:法国的ai研究者Kyutai推出开源实时语音多模态模型
- GraphRAG:微软开源 的下一代 RAG 技术
- Move AI 推出 Move API,实现 2D 视频转 3D 运动数据
- Cloudflare 推出一键阻止 AI 机器人的新工具
- 腾讯开源混元 Captioner 模型,优化文生图数据集生成
- 改变答题顺序会显著降低大模型准确率
- OpenDevin:卡内基梅隆大学教授创立 All Hands AI,推出开源 AI 软件代理 OpenDevin
- 漆远创立无限光年,获阿里投资进军可信大模型赛道
- 阿里发布 FunAudioLLM 开源项目,推出 SenseVoice 和 CosyVoice 两大语音模型
- 快手文生图大模型 Kolors 宣布开源
- 商汤科技发布 InternLM-XComposer2.5 视觉语言模型
- 穹彻智能推出具身大脑 Noematrix Brain,聚焦操作物理常识与行为决策
- 华中科技大学等团队推出 Holmes-VAD,实现视频异常检测与解释
- 可灵AI/Kling:快手视频生成大模型 可灵 AI Kling
- 彻底改变语言模型:全新架构TTT,ML模型代替RNN隐藏状态
- 新型TTT架构诞生,能否取代Transformer和Mamba成为最强大模型?
- DG4D/DreamGaussian4D:四维建模及运动控制模型
- CosyVoice:阿里的语音生成,支持多语言、音色和情感控制
- SenseVoice :阿里语音识别、语种识别、情感识别、声学事件分类或检测
- Seed-TTS:字节的的语音生成,太逼真太形象了
- Fish-Speech:开源的TTS项目,语音生成
- ollama:大模型运行平台,支持cpu运行大模型
- 当实时数字人遇上LLM
- CMD 下的基本指令
- 语音对话大模型:借助阿里的FunAudioLLM搭建语音对话模型
- CogVideo:智谱版Sora开源爆火,4090单卡运行,A6000可微调
-
功能模块
当实时数字人遇上LLM
正文
https://zhuanlan.zhihu.com/p/696337285
当实时数字人遇上LLM

Reshape
13 人赞同了该文章
背景
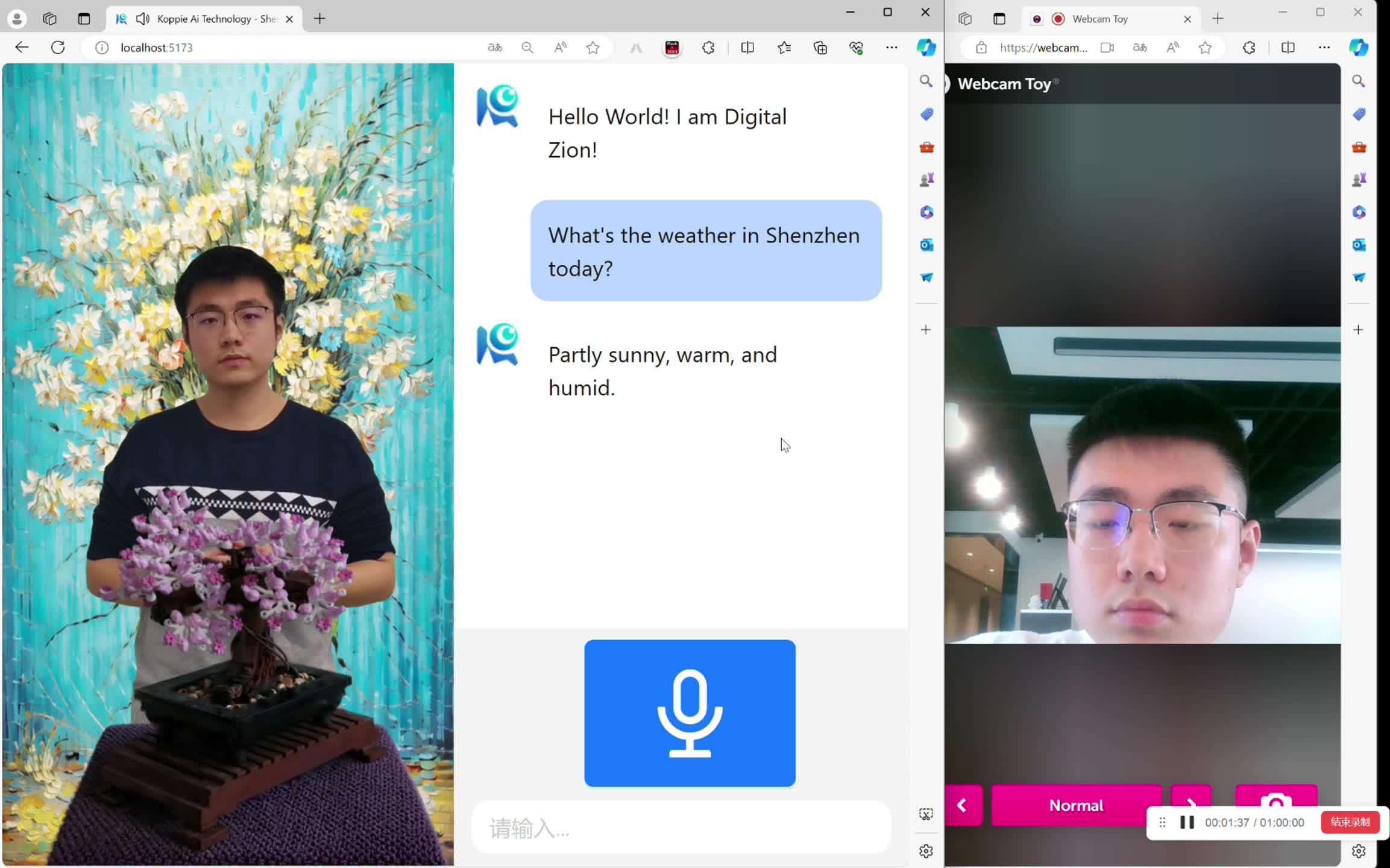
从去年开始,就感觉数字人在中国非常火:数字生命、直播带货、教育等等不一而足,大厂们也有自己的动作:


作为2019就做过2D数字人全管线的技术人员来说,很诧异数字人在2023重新火起来,因为从技术的角度,2D数字人技术并没有太多发展,我能想到的唯一解释就是,大语言模型作为“灵魂”火起来之后,需要一个“身体”来作为承载,大家自然就联想到了数字人。
五一假期不想出去人挤人,闲下来几天,正好可以把这个想法实现。
效果
00:11 / 00:53


技术实现
系统概述
我构建了一个将 ASR(自动语音识别)、唇同步、TTS(文本转语音)和流媒体技术与 LLM 集成的系统,以实现一个能够实时交互的数字人。
系统:Windows 11 + WSL
硬件:4090(3090应该也能实时)+i9-13900K
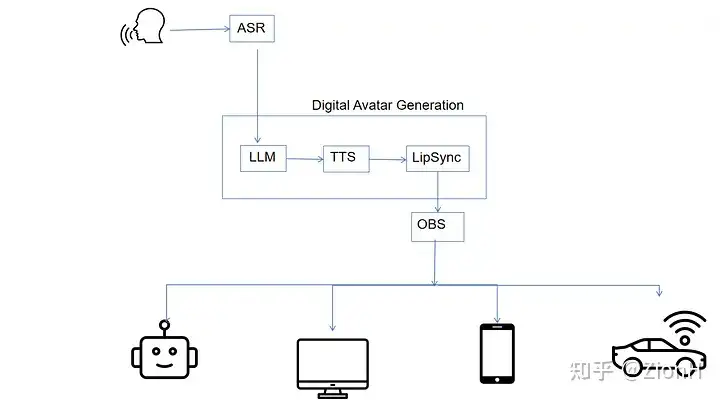
技术选型
在语音输入方面,我直接使用的Google WebKitGTK 的语音识别功能,参考:https://www.google.com/intl/en/chrome/demos/speech.html
在唇同步方面,我选择了 Wav2Lip。尽管近年来基于 NERF 的数字人(例如 ER-NERF)越来越受欢迎,它们利用 3D 先验知识并在实时场景中通常比 Wav2Lip 表现得更好,但我发现 Wav2Lip 的 2D 方法在输出质量上具有更高的稳定性。
对于 TTS(文本转语音)组件,我选择了 Bert-VITS2。这个项目的社区非常活跃,可能因为二次元比较多哈哈(+1),用一句老话来说就是:个个都是人才,说话又好听,我超喜欢在里面。最近似乎有更好的tts方案,比如:GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)
音频和视频流媒体对我来说是一个重大挑战,因为我以前没有相关经验。为了实现实时交互,我不能简单地将 Wav2Lip 的结果保存为视频然后使用 ffmpeg 流式传输,而是需要直接在内存中同步生成的音频和视频帧,然后进行流媒体传输。正在我毫无思路的时候,突然发现了这个项目:opencv_ffmpeg_streaming。它正是我所需要的:将 ffmpeg/avcodec 打包为 Python 接口。(窥探了下作者,是学物理的大佬,太强了)简单修改以后(把推单帧改成推batch),它完美地满足了我的需求,使我能够有效地流式传输神经网络推理结果。
在音频和视频帧的流媒体传输方面,我使用了 srs(简单实时服务器)Docker 来管理数据流。Python 服务器负责推理并将流发送到 srs Docker,然后它将该流转发到 OBS。最终,OBS 将流分发到各种终端设备。这一设置确保流媒体过程具有良好的稳健性和可扩展性,能够在不牺牲实时交互质量的前提下触达各种终端设备。
大语言模型我接的智谱(便宜+效果还行),但Web Search是我自己实现的。(吐槽一下,官网上说的Web Search用不了,问客服也回复不到点上)
实现细节
Wav2Lip 的工作过程分为两个主要阶段。第一阶段是面部检测,从视频帧中提取面部区域。这部分通常最耗时,但可以通过预处理来完成。我们保存每个视频帧的面部检测结果,从而简化了实时处理。第二阶段是唇部合成,对提取的图像进行操作,使其唇部动作与音频输入相匹配。为了提高这一阶段的性能,我用 TensorRT 进行了加速。
TTS 组件直接在 GPU 上进行推理,这已经非常快。
为了进一步减少初始帧的延迟,我实施了一种方法,将 LLM 输出按逗号和句号分段。这样可以进行流式生成,有助于减少语音输出的延迟,确保更流畅、更具互动性的用户体验。
srs推拉流,我直接选择的最常见的rtmp:RTMP Deploy | SRS(本来想用WebRTC的,但折腾了下,在浏览器上播放不出来,maybe是令牌没配对?有编解码的大佬可以指点一下)
一点思考
最近阿里的EMO和微软的VASA-1效果非常惊艳(可惜暂时没有开源),再加上GPT-5的来临,智能体全面融入我们的生活,到时候,我们的智能体交互的频率也许比与人类交互的频率还要高,是否人类与各种智能体的交互也需要一个全新的IM软件呢?
发布于 2024-05-07 13:29・IP 属地广东