-
《人工智能》目录
-
前言
-
数据中心
-
理论知识
-
基本安装
-
基本知识
-
Transformer
-
脉冲神经网络 (SNN)
-
数据处理
-
声音处理
- FunASR:阿里的语音识别
- Kaldi:ASR,语音识别,可以训练声学模型
- 星辰语音识别开源大模型:中国电信,【超多方言】ASR
- 最难方言温州话被攻克!中国电信语音大模型支持30种方言
- 播放音频文件
- 让 Python 来帮你朗读网页吧
- 从零开始搭建一个语音对话机器人
- Seed-TTS:字节发布高性能高逼真语音合成框架
- ChatTTS:语音合成
- edge-tts:语音合成,调用的微软edge的在线语音合成服务
- pyttsx3:语音转换
- python实现TTS离线语音合成
- StyleTTS2:one-shot语音风格迁移和逼真语音转换的论文阅读和代码实战
- Matcha-TTS:语音合成,
- Bailing-TTS:巨人网络支持普通话和方言混说的TTS大模型
-
图像处理
-
视频处理
-
文字处理
-
多模处理
-
动态记忆和自我反思
-
论文精选
-
大模型LLM
-
AIAgent
- 新一代AI模型Claude 3:有大学生智商,全面超越GPT-4
- FastChat——一个用于训练、部署和评估基于大型语言模型的聊天机器人的开放平台
- 谷歌DeepMind推出新一代药物研发AI模型AlphaFold 3
- LangChain-Chatchat (原 Langchain-ChatGLM)
- MaxKB本地私有大模型部署
- YOLO v10视觉目标检测算法本地端部署
- Fay数字人框架 助理版
- 百度开源 / Senta - 情感分析旨
- Moshi:法国的ai研究者Kyutai推出开源实时语音多模态模型
- GraphRAG:微软开源 的下一代 RAG 技术
- Move AI 推出 Move API,实现 2D 视频转 3D 运动数据
- Cloudflare 推出一键阻止 AI 机器人的新工具
- 腾讯开源混元 Captioner 模型,优化文生图数据集生成
- 改变答题顺序会显著降低大模型准确率
- OpenDevin:卡内基梅隆大学教授创立 All Hands AI,推出开源 AI 软件代理 OpenDevin
- 漆远创立无限光年,获阿里投资进军可信大模型赛道
- 阿里发布 FunAudioLLM 开源项目,推出 SenseVoice 和 CosyVoice 两大语音模型
- 快手文生图大模型 Kolors 宣布开源
- 商汤科技发布 InternLM-XComposer2.5 视觉语言模型
- 穹彻智能推出具身大脑 Noematrix Brain,聚焦操作物理常识与行为决策
- 华中科技大学等团队推出 Holmes-VAD,实现视频异常检测与解释
- 可灵AI/Kling:快手视频生成大模型 可灵 AI Kling
- 彻底改变语言模型:全新架构TTT,ML模型代替RNN隐藏状态
- 新型TTT架构诞生,能否取代Transformer和Mamba成为最强大模型?
- DG4D/DreamGaussian4D:四维建模及运动控制模型
- CosyVoice:阿里的语音生成,支持多语言、音色和情感控制
- SenseVoice :阿里语音识别、语种识别、情感识别、声学事件分类或检测
- Seed-TTS:字节的的语音生成,太逼真太形象了
- Fish-Speech:开源的TTS项目,语音生成
- ollama:大模型运行平台,支持cpu运行大模型
- 当实时数字人遇上LLM
- CMD 下的基本指令
- 语音对话大模型:借助阿里的FunAudioLLM搭建语音对话模型
- CogVideo:智谱版Sora开源爆火,4090单卡运行,A6000可微调
-
功能模块
Reflexion:具有动态记忆和自我反思的自主代理
正文
参考GitHub - noahshinn/reflexion: [NeurIPS 2023] Reflexion: Language Agents with Verbal Reinforcement Learning 地址:https://github.com/noahshinn/reflexion
在我们最近的论文“Reflexion: An Autonomous Agent with Dynamic Memory and Self-Reflection”中,论文地址: https://arxiv.org/abs/2303.11366 我们介绍了一个框架,允许 AI agent模拟类似人类的自我反思,并在ALFWorld和HotpotQA基准测试中评估其性能。我们的目标是创建 AI agent,通过反思失败并增强其结果来学习,就像人类一样。
在这篇文章中,我们描述了我们正在探索的与扩展 Reflexion 框架相关的一些想法,并简要介绍了我们观察到的有趣结果。我们用基于 Reflexion 的 GPT-4 agent在 HumanEval 上实现了最先进的pass@1结果 (88%),优于 GPT-4 (67.0%) 和 CodeT:带有生成测试的代码生成 (65.8%),这是以前最先进的标准。
1.Reflexion Without Definitive Ground Truth
人类以其从错误中学习的能力而著称。我们通常不会在第一次尝试时解决问题,但是当我们犯错误时,我们会通过自我反思和分析我们的失误来产生新的想法来完善我们的方法。在我们的论文中,我们使用一个用于解决问题评估的Ground Truth成功指标来公式化这个概念,并展示了我们如何迭代改进任务。然而,一些现实世界的情况没有明确的Ground Truth或单一的最佳解决方案。
为了解决这种情况,我们提出了一种再次反映人类解决问题的方法。当给定一个解决方案没有明确定义的任务时,我们通常会花时间根据我们的上下文理解,有意识或无意识地计划和创建内部测试套件。我们根据这些测试评估各种潜在的解决方案,并为每个解决方案分配一个置信水平。进行调整,直到解决方案可能满足所有或大部分测试,然后成为要执行的建议解决方案。在此方案中,满足所有或大多数内部测试的解决方案被接受为Ground Truth的解决方案,并且成功的机会取决于错误测试设计的概率。
这种方法可以应用于没有固定Ground Truth(pass@1)的各种问题,这些问题类似于许多跨越蛋白质或化学设计、建筑设计等领域的问题,或者我们每天遇到的简单问题。随着 LLM 和其他大型神经网络的使用,我们可能会看到Reflexion 在传统上由人类执行的任务中的广泛应用。例如,人工智能厨师可以根据你的状态创造菜肴,通过持续的反馈来完善食谱。同样,人工智能业务顾问可能会在没有预定义路径的情况下制定成功的业务战略。通过使用自我反思进行迭代学习,我们可以为无法获得具体Ground Truth 的问题开发高置信度的解决方案。
这个概念不仅适用于复杂的以人为中心的问题,也适用于更简单的基于文本的问题,如代码实现。由于开发人员经常实现程序,因此他们参与代码编写、执行和调试的迭代循环。通常,程序员花在解决现有代码中的错误上的时间比从头开始编写新代码的时间要多。这种迭代特性使程序实现成为 Reflexion 应用的理想选择。
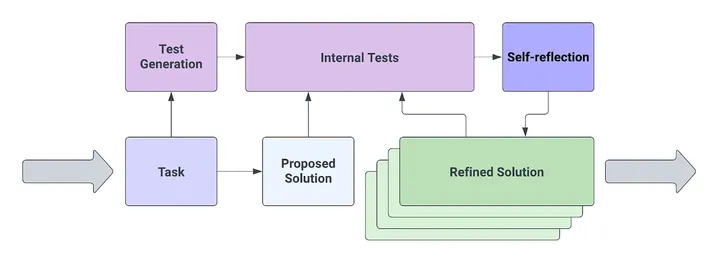
2.将 Reflexion 应用于 HumanEval
HumanEval 数据集已成为衡量代码生成准确性的广泛认可的基准。我们基于 Reflexion 的智能体以 HumanEval 数据集为基准,准确率达到 88%,,超过了 GPT-4 (67%)、CodeT (65.8%) 和 PaLM (26.2%)。
通常,在程序实现的初始阶段,程序员会设计内部测试,他们可以用来评估未来实现的性能。这使他们能够不断完善代码以满足内部测试的约束。当所有内部测试都通过时,程序员将满怀信心地推动他们的代码,因为他们已经产生了一个解决方案,该解决方案已经完成了任务,以他们对当前问题的最佳理解。
虽然人们可以使用各种方法来实际编程,但在编程竞赛中采用的方法可以很好地理解程序实施的最佳方法。在此类竞赛中,参赛者通常被允许在外部编辑器中编写他们的实现并运行自行设计的测试用例。一些竞争指南甚至可能允许竞争对手在“可见”测试用例的子集上评估其实现。在程序实现中,这就是测试驱动开发(TDD)的思想。TDD的工作原理如下:(1)人类接收到技术问题的描述和目标特征列表;(2)人类设计了一套单元测试,以捕捉程序的理想行为,以最好地理解技术问题;(3)人类用代码编写实现;(4)人类在他们的程序上运行他们的测试套件;(5)如果所有测试都通过了,并且人类对测试的设计和覆盖率有信心,他们将以高置信度将他们的代码推送到代码库。
然而,用于代码生成方法的 TDD 并不新鲜。 CodeT:使用生成的测试生成代码是一种使用双重执行协议的方法,它涉及内部测试生成和执行,以评估生成的样本之间的置信度。在 GPT-4 公开发布之前,CodeT 在 HumanEval 上以 65.8% 的准确率保持最先进的标准。CodeT pass@1完成的管道解释如下:(1) 为代理提供函数签名和文档字符串 (2) 代理生成内部单元测试的集合,但无法访问Ground Truth (3) 代理生成函数体实现的集合 (4) 代理评估内部单元测试的实现 (5) 代理返回通过最多测试的实现。
CodeT 方法可提高性能,因为函数体样本的数量会增加。虽然这种方法允许从基本状态(给定的函数签名和文档字符串)探索较大的状态空间,但它不允许代理从以前的高置信度状态开始探索,这些状态通过对其内部测试的评估进行量化。这个想法可以通过一个例子更直观地解释。假设人类的任务是在一所房子里找到一个物体,该物体可能包含几个房间、抽屉和橱柜,但有一个限制,即他们一次只能检查房子的 1 个区域。如果应用了等效的 CodeT,他们将设计一个内部测试套件,例如他们正在寻找的对象的描述,然后,如果他们找到与描述匹配的对象,他们可以非常自信地报告他们已经完成了任务。在他们的搜索样本中,例如“检查室 1”、“检查室 2”等,它们找到对象的能力会随着样本数量的增加而增加。但是,如果物体隐藏得很好,由于缺乏对过去尝试的记忆,人类很有可能不会探索可以找到该物体的区域。
在程序开发中,这等同于试图盲目地生成 N 个建议的解决方案,并希望 1 个样本能够满足内部测试的约束。我们的 Reflexion 论文展示了一种方法,允许代理改进他们过去的方法,使其与地面实况解决方案保持一致。但是,在pass@1指标等情况下,Ground Truth不可用。因此,我们使用带有轻松成功评估的 Reflexion 来探索起始状态之外的高置信度状态,以找到满足内部测试的解决方案,同时保持对pass@1标准的遵守。
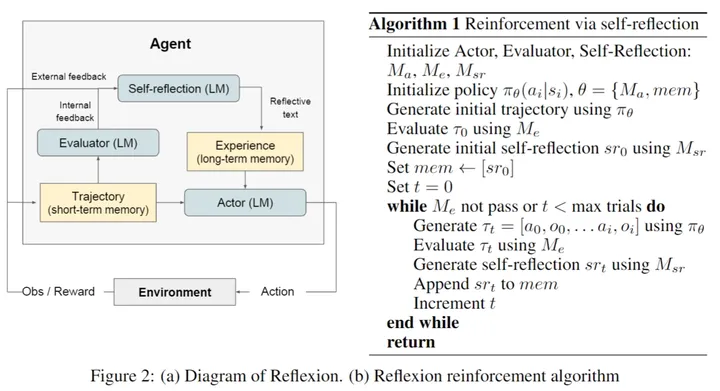
3.Relaxing Success Evaluation
通过使用 Reflexion 迭代优化当前的实现,我们正在将“accuracy bottleneck”从正确的句法和语义代码生成转移到正确的句法和语义test generation。从理论上讲,测试生成应该比代码生成code generation 更容易完成。根据这个假设,我们假设如果一个智能体可以设计多样化和准确的测试,那么他们可以使用内部测试来迭代地优化它们的实现,然后智能体的准确性可以重新定义为它生成准确测试的能力。
实现
测试生成test generation
测试生成方法的灵感来自 https://github.com/microsoft/CodeT 的 CodeT:使用生成的测试生成代码。 https://github.com/microsoft/CodeT.
函数体生成 Function body generation
代码实现生成方法的灵感来自 https://github.com/microsoft/CodeT 的 CodeT:使用生成的测试 https://github.com/microsoft/CodeT生成代码。
单元测试执行 Unit test execution
实现单元测试执行是为了为代理提供以下功能:(1) 评估 - 评估其在内部单元测试中的当前准确性,以及 (2) 反馈 - 每个测试的详细日志通过/失败状态,其中包含失败测试的错误类型或输出值,例如“string”、5、AssertionError、SyntaxError 等。为了评估内部单元测试的准确性,我们将当前函数实现与每个内部单元测试配对。对于每个测试,如果测试通过,我们会将其添加到已通过测试的列表中。如果测试失败,我们使用特定于语言的抽象语法树(在本例中为 Python AST 模块)来构造函数调用,使用失败测试中的相同参数来捕获错误类型或返回输出,然后将其添加到失败测试列表中。示例如下所示:
函数调用构造
assert func(x0, y0) == z0 → func(x0, y0)
assert func(x3, y3) == z3 → func(x3, y3)
assert func(x4, y4) == z4 → func(x4, y4)
反馈示例输出
Passed tests:
assert func(x0, y0) == z0
assert func(x3, y3) == z3
assert func(x4, y4) == z4
Failed tests:
assert func(x1, y1) == z1 # output: AssertionError
assert func(x2, y2) == z2 # output: 5
自我反思生成 Self-reflection generation
在反思论文的基础上,我们的目标是进一步隔离单个问题以实现迭代改进。对于根植于自然语言的问题,通常会看到需要 LLM 来增强两个或多个子任务的性能的实现。具体来说,我们要隔离两个任务:(1) 错误识别——例如,“此函数中的第二个 for 循环是不必要的,可能会导致运行时错误,如测试 #1 和 #2 所示”,以及 (2) 实现更正——例如,“这是一个带有更正的更新实现:python\n <new code>”。为了隔离这些任务,我们对 LLM 进行了两次调用。第一个调用基于自我反思生成自然语言指令,而第二个调用生成新的实现,考虑内部测试反馈、以前的实现和修订版本的指令。
4.Apply Reflexion
通过将成功标准放宽到内部测试准确性,我们能够执行一个尊重pass@1性能标准的迭代反馈循环。在这篇文章中,我们希望我们能够为未来的 Reflexion 实现提供有意义的想法。我们鼓励其他人应用 Reflexion 来使智能体能够解决目前由人类智能主导的各种复杂任务。

参考
GitHub - noahshinn/reflexion: [NeurIPS 2023] Reflexion: Language Agents with Verbal Reinforcement Learning 地址:https://github.com/noahshinn/reflexion