-
《人工智能》目录
-
前言
-
数据中心
-
理论知识
-
基本安装
-
基本知识
-
Transformer
-
脉冲神经网络 (SNN)
-
数据处理
-
声音处理
- FunASR:阿里的语音识别
- Kaldi:ASR,语音识别,可以训练声学模型
- 星辰语音识别开源大模型:中国电信,【超多方言】ASR
- 最难方言温州话被攻克!中国电信语音大模型支持30种方言
- 播放音频文件
- 让 Python 来帮你朗读网页吧
- 从零开始搭建一个语音对话机器人
- Seed-TTS:字节发布高性能高逼真语音合成框架
- ChatTTS:语音合成
- edge-tts:语音合成,调用的微软edge的在线语音合成服务
- pyttsx3:语音转换
- python实现TTS离线语音合成
- StyleTTS2:one-shot语音风格迁移和逼真语音转换的论文阅读和代码实战
- Matcha-TTS:语音合成,
- Bailing-TTS:巨人网络支持普通话和方言混说的TTS大模型
-
图像处理
-
视频处理
-
文字处理
-
多模处理
-
动态记忆和自我反思
-
论文精选
-
大模型LLM
-
AIAgent
- 新一代AI模型Claude 3:有大学生智商,全面超越GPT-4
- FastChat——一个用于训练、部署和评估基于大型语言模型的聊天机器人的开放平台
- 谷歌DeepMind推出新一代药物研发AI模型AlphaFold 3
- LangChain-Chatchat (原 Langchain-ChatGLM)
- MaxKB本地私有大模型部署
- YOLO v10视觉目标检测算法本地端部署
- Fay数字人框架 助理版
- 百度开源 / Senta - 情感分析旨
- Moshi:法国的ai研究者Kyutai推出开源实时语音多模态模型
- GraphRAG:微软开源 的下一代 RAG 技术
- Move AI 推出 Move API,实现 2D 视频转 3D 运动数据
- Cloudflare 推出一键阻止 AI 机器人的新工具
- 腾讯开源混元 Captioner 模型,优化文生图数据集生成
- 改变答题顺序会显著降低大模型准确率
- OpenDevin:卡内基梅隆大学教授创立 All Hands AI,推出开源 AI 软件代理 OpenDevin
- 漆远创立无限光年,获阿里投资进军可信大模型赛道
- 阿里发布 FunAudioLLM 开源项目,推出 SenseVoice 和 CosyVoice 两大语音模型
- 快手文生图大模型 Kolors 宣布开源
- 商汤科技发布 InternLM-XComposer2.5 视觉语言模型
- 穹彻智能推出具身大脑 Noematrix Brain,聚焦操作物理常识与行为决策
- 华中科技大学等团队推出 Holmes-VAD,实现视频异常检测与解释
- 可灵AI/Kling:快手视频生成大模型 可灵 AI Kling
- 彻底改变语言模型:全新架构TTT,ML模型代替RNN隐藏状态
- 新型TTT架构诞生,能否取代Transformer和Mamba成为最强大模型?
- DG4D/DreamGaussian4D:四维建模及运动控制模型
- CosyVoice:阿里的语音生成,支持多语言、音色和情感控制
- SenseVoice :阿里语音识别、语种识别、情感识别、声学事件分类或检测
- Seed-TTS:字节的的语音生成,太逼真太形象了
- Fish-Speech:开源的TTS项目,语音生成
- ollama:大模型运行平台,支持cpu运行大模型
- 当实时数字人遇上LLM
- CMD 下的基本指令
- 语音对话大模型:借助阿里的FunAudioLLM搭建语音对话模型
- CogVideo:智谱版Sora开源爆火,4090单卡运行,A6000可微调
-
功能模块
Kaldi:ASR,语音识别,可以训练声学模型
正文
一、概述
什么是Kaldi?Kaldi是ASR的工具箱,可以训练声学模型,也可以使用已有的算法提取声学特征。
什么是声学模型?它是音素声学信息的统计表示。声学模型由标注好的数据训练而来。声学模型可以用于自动语音识别,也可以用于强制对齐。
二、安装
Kaldi可以直接下载安装,我只试过在Ubuntu中编译。使用以下命令下载源码:
git clone https://github.com/kaldi-asr/kaldi.git kaldi --origin upstream
下载的文件中有INSTALL文档,按照步骤安装即可。下面的步骤仅供参考,有任何疑问可以上网搜索,一般都可以解决。
cd kaldi/tools extras/check_dependencies.sh make cd kaldi/src ./configure make depend make
三、结构
编译后的Kaldi有几个文件夹,分别是egs,src,tools,misc等。最常用的是egs和src。
egs的意思是examples,即使用样例。内容包括大部分大型开源数据库的训练流程,如WSJC,TIMIT,RM等。
src是源码,可以读一下,了解作者的工作思路。不读也不要紧,脚本里直接调用也没问题。
每一个训练流程文件夹都有标准的结构,比如egs/rm/s5文件夹中,有run.sh,cmd.sh和path.sh几个脚本文件。文件夹中还有conf,data,exp,local,steps和utils等子文件夹。data文件夹存储的是转写、词典等数据,exp存储的是训练的成果、脚本和声学模型等。
下图的结构供参考:
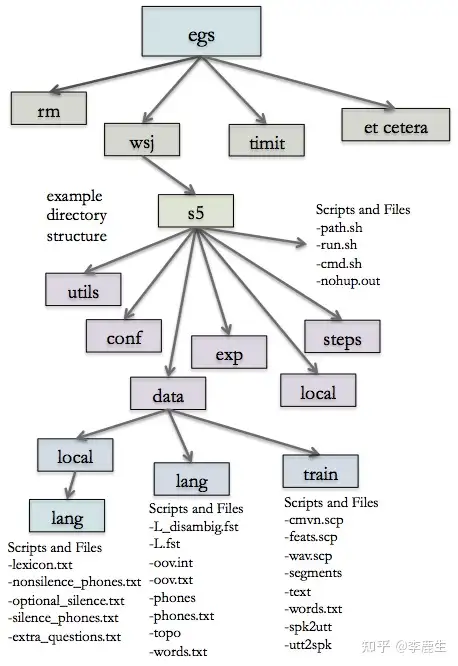
四、训练概览
脚本很重要,但先了解训练声学模型的基本流程更为必要。
(一)获取语音数据的转写
有时候还需要每一句的起止时间。
(二)将转写调为标准格式
每一句的起止时间、每一句的说话人ID、词和音素的列表。
(三)提取特征
一般用MFCC,有时候也会PLP,如果用比较深的网络,F-bank也可以用。
(四)训练单音素模型
顾名思义,就是只包含单个音素信息的声学模型。
(五)将音频与声学模型对齐
在训练阶段,模型参数基本确定下来。但如果能将训练与对齐循环往复,效果会更好,可以用Viterbi算法、EM或前向后向算法。
(六)训练三音素模型
并非所有的三音素都会出现,可以用决策树聚类以减少参数。
(七)将音频与声学模型对齐
实际是第五步的重复。
一些算法:
1、Delta+delta-delta training。这是MFCC特征中经常用到的步骤,实质是求导(离散情况下是差分方程),以获取动态特征。
2、LDA-MLLT是线性判别分析和极大似然线性变换的简称,LDA就是Fisher判别分析,本质是一种降维。MLLT的目的是作说话人之间的归整。
3、SAT是说话人适应性训练,也是一种归一化算法。
对齐算法是fMLLR,即特征空间极大似然线性回归。
五、训练
(一)准备文件夹
为任务新建文件夹。
比如:
mkdir mycorpus
在mycorpus文件夹中依照其他egs中的文件夹建立文件夹结构。
在此文件中建立软连接,以使用wsj文件夹中的steps,utils,src等文件,同时把path.sh拷贝过来。注意脚本文件中的地址要根据实际的地址更新。
比如:
cd mycorpus ln -s ../wsj/s5/steps ln -s ../wsj/s5/utils ln -s ../../src cp ../wsj/s5/path.sh
mycorpus比s5要高一层,所以path.sh中的路径也要上移一层:
# 将以下路径 export KALDI_ROOT='pwd'/../../.. # 改为 export KALDI_ROOT='pwd'/../..
然后在mycorpus文件夹中建立exp,conf,data子文件夹。data中建立train,lang,local和local/lang文件夹。如下:
cd mycorpus mkdir exp mkdir conf mkdir data cd data mkdir train mkdir lang mkdir local cd local mkdir lang
(二)为data/train创建文件
data/train中的文件包含音频文件、转写、说话人等信息。包括的文件有:
text
segments
wav.scp
utt2spk
spk2utt
1. text
text是逐句转写,格式如下:
utt_id XXXXXXXX……
utt_id是utterance ID。
示例如下:
110236_20091006_82330_F_0001 I’M WORRIED ABOUT THAT
110236_20091006_82330_F_0002 AT LEAST NOW WE HAVE THE BENEFIT
110236_20091006_82330_F_0003 DID YOU EVER GO ON STRIKE
…
120958_20100126_97016_M_0285 SOMETIMES LESS IS BETTER
120958_20100126_97016_M_0286 YOU MUST LOVE TO COOK
有了text后,词表只包含text中出现的词。使用以下命令:
cut -d 'my delimiter' -f 2- text | sed 's/ /\n/g' | sort -u > words.txt
再用python脚本出去重即可。
一个示例脚本filter_dict.py将words.txt和lexicon.txt作为输入,可以根据需要修改。
import os
ref = dict()
phones = dict()
with open("../lexicon") as f:
for line in f:
line = line.strip()
columns = line.split(" ", 1)
word = columns[0]
pron = columns[1]
try:
ref[word].append(pron)
except:
ref[word] = list()
ref[word].append(pron)
print ref
lex = open("data/local/lang/lexicon.txt", "wb")
with open("data/train/words.txt") as f:
for line in f:
line = line.strip()
if line in ref.keys():
for pron in ref[line]:
lex.write(line + " " + pron+"\n")
else:
print "Word not in lexicon:" + line在lexicon中需要加入<oov> <oov>,这是系统需要,表示out of vocabulary。
2. segments
segments表示的是utterance的起止时间。格式如下:
utt_id file_id start_time end_time
示例文件如下:
110236_20091006_82330_F_001 110236_20091006_82330_F 0.0 3.44
110236_20091006_82330_F_002 110236_20091006_82330_F 4.60 8.54
110236_20091006_82330_F_003 110236_20091006_82330_F 9.45 12.05
110236_20091006_82330_F_004 110236_20091006_82330_F 13.29 16.13
110236_20091006_82330_F_005 110236_20091006_82330_F 17.27 20.36
110236_20091006_82330_F_006 110236_20091006_82330_F 22.06 25.46
110236_20091006_82330_F_007 110236_20091006_82330_F 25.86 27.56
110236_20091006_82330_F_008 110236_20091006_82330_F 28.26 31.24
…
120958_20100126_97016_M_282 120958_20100126_97016_M 915.62 919.67
120958_20100126_97016_M_283 120958_20100126_97016_M 920.51 922.69
120958_20100126_97016_M_284 120958_20100126_97016_M 922.88 924.27
120958_20100126_97016_M_285 120958_20100126_97016_M 925.35 927.88
120958_20100126_97016_M_286 120958_20100126_97016_M 928.31 930.51
3. wav.scp
wav.scp是每个音频文件的路径。格式如下:
file_id path/file
示例如下:
110236_20091006_82330_F path/110236_20091006_82330_F.wav
111138_20091215_82636_F path/111138_20091215_82636_F.wav
111138_20091217_82636_F path/111138_20091217_82636_F.wav
如果格式不用wav,用sox作批量转换即可。如:
file_id path/sox audio.mp3 -t wav -r 8000 -c 1 - remix 2|
4. utt2spk
从名字可以看出,它是utterance和说话人之间的映射。格式如下:
utt_id spkr
示例如下:
110236_20091006_82330_F_0001 110236
110236_20091006_82330_F_0002 110236
110236_20091006_82330_F_0003 110236
110236_20091006_82330_F_0004 110236
这些信息在segments中都有,所以可以直接用命令生成:
cat data/train/segments | cut -f 1 -d ' ' | perl -ane 'chomp; @F = split "_", $_; print $_ . " " . @F[0] . "\n";' > data/train/utt2spk
5. spk2utt
它是utt2spk的转换,可以直接生成:
utils/fix_data_dir.sh data/train
(三)创建data/local/lang中的文件
逻辑与第(二)部分一样,需要以下文件:
lexicon.txt
nonsilence_phones.txt
optional_silence.txt
silence_phones.txt
extra_questions.txt (optional)
1. lexicon.txt
这是发音词典。如下:
WORD W ER D
LEXICON L EH K S IH K AH N
2. nonsilence_phones.txt
用下面的命令可以自动生成:
cut -d ' ' -f 2- lexicon.txt | sed 's/ /\n/g' | sort -u > nonsilence_phones.txt
3. silence_phones.txt
用下面的命令生成:
echo –e 'SIL'\\n'oov' > silence_phones.txt
4. optional_silence.txt
用下面的命令生成:
echo 'SIL' > optional_silence.txt
5. extra_questions.txt
(四) 为data/lang创建文件
有了data/local/lang中的文件后,可以用脚本自动生成data/lang中的文件。
cd mycorpus utils/prepare_lang.sh data/local/lang 'OOV' data/local/ data/lang # where the underlying argument structure is: utils/prepare_lang.sh <dict-src-dir> <oov-dict-entry> <tmp-dir> <lang-dir>
创建的文件包括L.fst,L_disambig.fst,http://oov.int,oov.txt,phones.txt,topo,words.txt,phones。
(五)并行化设置
Kaldi中的脚本run.pl,queue.pl和slurm.pl可以作并行化处理。
run.pl是在本地机器上跑任务。
queue.pl可以在许多机器上分配任务。
slurm.pl可以在更多机器上分配任务。
我只有本地机器,所以用下面的脚本:
cd mycorpus vim cmd.sh # Press i to insert; esc to exit insert mode; # ‘:wq’ to write and quit; ‘:q’ to quit normally; # ‘:q!’ to quit forcibly (without saving) # Insert the following text in cmd.sh train_cmd="run.pl" decode_cmd="run.pl"
然后运行:
cd mycorpus ./cmd.sh
(六)为conf创建文件
这个文件就是mfcc.conf,包括:
-use-energy=false
-sample-frequency=16000
(七)提取MFCC
直接用以下脚本提取即可:
cd mycorpus mfccdir=mfcc x=data/train steps/make_mfcc.sh --cmd "$train_cmd" --nj 16 $x exp/make_mfcc/$x $mfccdir steps/compute_cmvn_stats.sh $x exp/make_mfcc/$x $mfccdir
(八)单音素训练与对齐
训练的第一步是单音素训练,此处的训练集只用总训练集的一小部分即可。下面的脚本是训练步骤:
cd mycoupus utils/subset_data_dir.sh --first data/train 10000 data/train_10k
所有的训练步骤都差不多,除了单音素训练,因为此时还没有任何模型。需要的参数包括:
- Location of the acoustic data: `data/train` - Location of the lexicon: `data/lang` - Source directory for the model: `exp/lastmodel` - Destination directory for the model: `exp/currentmodel`
下面的代码是训练步骤:
steps/train_mono.sh --boost-silence 1.25 --nj 10 --cmd "$train_cmd" \ data/train_10k data/lang exp/mono_10k
对齐脚本的参数如下:
- Location of the acoustic data: `data/train` - Location of the lexicon: `data/lang` - Source directory for the model: `exp/currentmodel` - Destination directory for the alignment: `exp/currentmodel_ali`
脚本如下:
steps/align_si.sh --boost-silence 1.25 --nj 16 --cmd "$train_cmd" \ data/train data/lang exp/mono_10k exp/mono_ali || exit 1;
下图是现在的文件夹结构:

(九)三音联训练与对齐
三音联训练的时候,HMM状态需要额外的参数。此处使用2000个HMM状态和10000个高斯。假如词典有50个音素,可以每个状态一个音素。但是,每个音素都会有较大的变化,所有至少需要对每个音素做三个状态,即150个状态。如果有2000个状态的话,模型可以决定将同一音素的不同状态对应到不同的HMM状态中。这些状态与HMM状态一一对应,因此可以换用。
高斯数与数据量、模型特点、状态数都有关,此处用10000个也是试验的结果。如下:
steps/train_deltas.sh --boost-silence 1.25 --cmd "$train_cmd" 2000 10000 data/train data/lang exp/mono_ali exp/tri1 || exit 1;
对齐用下面的脚本:
steps/align_si.sh --nj 24 --cmd "$train_cmd" \ data/train data/lang exp/tri1 exp/tri1_ali || exit 1;
用delta等信息训练用下面的脚本:
steps/train_deltas.sh --cmd "$train_cmd" 2500 15000 data/train data/lang exp/tri1_ali exp/tri2a || exit 1;
对齐用下面的脚本:
steps/align_si.sh --nj 24 --cmd "$train_cmd" --use-graphs true data/train data/lang exp/tri2a exp/tri2a_ali || exit 1;
训练LDA-MLLT三音联:
steps/train_lda_mllt.sh --cmd "$train_cmd" 3500 20000 data/train data/lang exp/tri2a_ali exp/tri3a || exit 1;
再对齐:
steps/align_fmllr.sh --nj 32 --cmd "$train_cmd" data/train data/lang exp/tri3a exp/tri3a_ali || exit 1;
训练SAT三音联:
steps/train_sat.sh --cmd "$train_cmd" 4200 40000 data/train data/lang exp/tri3a_ali exp/tri4a || exit 1;
对齐:
steps/align_fmllr.sh --cmd "$train_cmd" data/train data/lang exp/tri4a exp/tri4a_ali || exit 1;
六、强制对齐
创立声学模型之后,Kaldi可以在转写的基础上强制对齐。Montreal Forced Aligner就是按照这样的路线写的对齐工具。
全部流程的成果将以TextGrid文件的形式输出。
(一)准备对齐文件
对于新的任务,需要依照之前在data/train创建的文件,再创建一套新的文件。
cd mycorpus/data mkdir alignme
这些文件是text,segments,wav.scp,utt2spk,spk2utt。
(二)提取MFCC
cd mycorpus mfccdir=mfcc for x in data/alignme do steps/make_mfcc.sh --cmd "$train_cmd" --nj 16 $x exp/make_mfcc/$x $mfccdir utils/fix_data_dir.sh data/alignme steps/compute_cmvn_stats.sh $x exp/make_mfcc/$x $mfccdir utils/fix_data_dir.sh data/alignme done
(三)对齐数据
cd mycorpus steps/align_si.sh --cmd "$train_cmd" data/alignme data/lang exp/tri4a exp/tri4a_alignme || exit 1;
(四)提取对齐文件
一是要获取CTM输出,即time-marked conversation文件。此文件包含时间对齐的音素信息,格式如下:
utt_id channel_num start_time phone_dur phone_id
下面的脚本从tri4a_alignme文件夹中提取CTM输出,使用的声学模型在tri4a中。
cd mycorpus
for i in exp/tri4a_alignme/ali.*.gz;
do src/bin/ali-to-phones --ctm-output exp/tri4a/final.mdl \
ark:"gunzip -c $i|" -> ${i%.gz}.ctm;
done;将CTM文件拼接在一起:
cd mycorpus/exp/tri4a_alignme cat *.ctm > merged_alignment.txt
CTM输出的是utterance的起始时间,需要对照segments文件才能获取文件时间。phone ID也还转换为对应的phone,可参考phones.txt转换。
用以下脚本:
#!/bin/sh
# id2phone.R
#
#
# Created by Eleanor Chodroff on 3/24/15.
#
phones <- read.table("/Users/Eleanor/mycorpus/recipefiles/phones.txt", quote="\"")
segments <- read.table("/Users/Eleanor/mycorpus/recipefiles/segments.txt", quote="\"")
ctm <- read.table("/Users/Eleanor/mycorpus/recipefiles/merged_alignment.txt", quote="\"")
names(ctm) <- c("file_utt","utt","start","dur","id")
ctm$file <- gsub("_[0-9]*$","",ctm$file_utt)
names(phones) <- c("phone","id")
names(segments) <- c("file_utt","file","start_utt","end_utt")
ctm2 <- merge(ctm, phones, by="id")
ctm3 <- merge(ctm2, segments, by=c("file_utt","file"))
ctm3$start_real <- ctm3$start + ctm3$start_utt
ctm3$end_real <- ctm3$start_utt + ctm3$dur
write.table(ctm3, "Users/Eleanor/mycorpus/recipefiles/final_ali.txt", row.names=F, quote=F, sep="\t")返回final_ali.txt文件后,需要将之分割。
#!/bin/sh
# splitAlignments.py
#
#
# Created by Eleanor Chodroff on 3/25/15.
#
#
#
import sys,csv
results=[]
#name = name of first text file in final_ali.txt
#name_fin = name of final text file in final_ali.txt
name = "110236_20091006_82330_F"
name_fin = "120958_20100126_97016_M"
try:
with open("final_ali.txt") as f:
next(f) #skip header
for line in f:
columns=line.split("\t")
name_prev = name
name = columns[1]
if (name_prev != name):
try:
with open((name_prev)+".txt",'w') as fwrite:
writer = csv.writer(fwrite)
fwrite.write("\n".join(results))
fwrite.close()
#print name
except Exception, e:
print "Failed to write file",e
sys.exit(2)
del results[:]
results.append(line[0:-1])
else:
results.append(line[0:-1])
except Exception, e:
print "Failed to read file",e
sys.exit(1)
# this prints out the last textfile (nothing following it to compare with)
try:
with open((name_prev)+".txt",'w') as fwrite:
writer = csv.writer(fwrite)
fwrite.write("\n".join(results))
fwrite.close()
#print name
except Exception, e:
print "Failed to write file",e
sys.exit(2)
# phons2words.py
#
#
# Created by Eleanor Chodroff on 2/07/16.
import sys,re,glob
pron_ali=open("pron_alignment.txt",'w')
pron=[]
files = glob.glob('[1-9]*.txt')
# process each file
for filei in files:
print filei
f = open(filei, 'r')
header = True
pron_ali.write('\n')
for line in f:
if header:
header = False
continue
line=line.split("\t")
file=line[1]
file = file.strip()
phon_pos=line[6]
#print phon_pos
if phon_pos == "SIL":
phon_pos = "SIL_S"
phon_pos=phon_pos.split("_")
phon=phon_pos[0]
pos=phon_pos[1]
#print pos
if pos == "B":
start=line[9]
pron.append(phon)
if pos == "S":
start=line[9]
end=line[10]
pron.append(phon)
pron_ali.write(file + '\t' + ' '.join(pron) +'\t'+ str(start) + '\t' + str(end))
pron=[]
if pos == "E":
end=line[10]
pron.append(phon)
pron_ali.write(file + '\t' + ' '.join(pron) +'\t'+ str(start) + '\t' + str(end))
pron=[]
if pos == "I":
pron.append(phon)
#!/usr/bin/python
# -*- coding: utf-8 -*-
#
# phons2words.py
#
#
# Created by Eleanor Chodroff on 2/07/16.
#### issues with unicode (u'')
import sys,csv,os,os.path,re,codecs
# make dictionary of word: prons
lex = {}
with codecs.open("lexicon.txt", "rb", "utf-8") as f:
for line in f:
line = line.strip()
columns = line.split("\t")
word = columns[0]
pron = columns[1]
#print pron
try:
lex[pron].append(word)
except:
lex[pron] = list()
lex[pron].append(word)
# open file to write
word_ali = codecs.open("word_alignment.txt", "wb", "utf-8")
# read file with most information in it
with codecs.open("pron_alignment.txt", "rb", "utf-8") as f:
for line in f:
line = line.strip()
line = line.split("\t")
# get the pronunciation
pron = line[1]
# look up the word from the pronunciation in the dictionary
word = lex.get(pron)
word = word[0]
file = line[0]
start = line[2]
end = line[3]
word_ali.write(file + '\t' + word + '\t' + start + '\t' + end + '\n')(五)生成TextGrid
为每个txt文件添加文件头,以符合textgrid文件的格式。
cd ~/Desktop mkdir tmp header="/Users/Eleanor/Desktop/header.txt" # direct the terminal to the directory with the newly split session files # ensure that the RegEx below will capture only the session files # otherwise change this or move the other .txt files to a different folder cd mycorpus/forcedalignment for i in *.txt; do cat "$header" "$i" > /Users/Eleanor/Desktop/tmp/xx.$$ mv /Users/Eleanor/Desktop/tmp/xx.$$ "$i" done;
上述脚本需要在桌面有个tmp文件夹,同时需要包括以下文件头的文件:
file_utt file id ali startinutt dur phone start_utt end_utt start end
下述Praat脚本文件从txt文件生成音素对齐标注文件:
# Created 27 March 2015 E. Chodroff dir$ = "/Users/Eleanor/mycorpus" Create Strings as file list... list_txt 'dir$'/*.txt nFiles = Get number of strings for i from 1 to nFiles select Strings list_txt filename$ = Get string... i basename$ = filename$ - ".txt" txtname$ = filename$ - ".txt" Read from file... 'dir$'/'basename$'.wav dur = Get total duration To TextGrid... "kaldiphone" #pause 'txtname$' select Strings list_txt Read Table from tab-separated file... 'dir$'/'txtname$'.txt Rename... times nRows = Get number of rows Sort rows... start for j from 1 to nRows select Table times startutt_col$ = Get column label... 5 start_col$ = Get column label... 10 dur_col$ = Get column label... 6 phone_col$ = Get column label... 7 if j < nRows startnextutt = Get value... j+1 'startutt_col$' else startnextutt = 0 endif start = Get value... j 'start_col$' phone$ = Get value... j 'phone_col$' dur = Get value... j 'dur_col$' end = start + dur select TextGrid 'basename$' int = Get interval at time... 1 start+0.005 if start > 0 & startnextutt = 0 Insert boundary... 1 start Set interval text... 1 int+1 'phone$' Insert boundary... 1 end elsif start = 0 Set interval text... 1 int 'phone$' elsif start > 0 Insert boundary... 1 start Set interval text... 1 int+1 'phone$' endif #pause endfor #pause Write to text file... 'dir$'/'basename$'.TextGrid select Table times plus Sound 'basename$' plus TextGrid 'basename$' Remove endfor
以下脚本从word_alignment.txt文件生成单词对齐文件:
# Created 8 Feb 2016 E. Chodroff dir$ = "/Volumes/MIXER6_cogsci/CzechNijmegen/alignment/tri1_ali_utf8" dir2$ = "/Volumes/MIXER6_cogsci/CzechNijmegen/wavfiles" word_ali$ = "word_alignment" Read Table from tab-separated file... 'dir$'/'word_ali$'.txt nRows = Get number of rows col_file$ = Get column label... 1 col_start$ = Get column label... 3 col_end$ = Get column label... 4 col_word$ = Get column label... 2 file1$ = Get value... 1 'col_file$' Open long sound file... 'dir2$'/'file1$'.wav To TextGrid... "word" for i from 1 to nRows select Table 'word_ali$' # open new sound file if necessary ## compare filename from current row to previous row if i = 1 file2$ = Get value... i 'col_file$' else file1$ = Get value... i-1 'col_file$' file2$ = Get value... i 'col_file$' endif ## if filenames are not the same, open new sound file if file2$ != file1$ select TextGrid 'file1$' Save as text file... 'dir$'/'file1$'_word.TextGrid #pause just saved textgrid select LongSound 'file1$' plus TextGrid 'file1$' Remove Open long sound file... 'dir2$'/'file2$'.wav To TextGrid... "word" endif # start marking textgrid select Table 'word_ali$' start = Get value... i 'col_start$' end = Get value... i 'col_end$' word$ = Get value... i 'col_word$' ## get start time of next word in case you need to mark the end time of current if i < nRows startnextword = Get value... i+1 'col_start$' endif select TextGrid 'file2$' int = Get interval at time... 1 start+0.005 ## if you're at the end of a file, mark the end of the last word if start > 0 & startnextword = 0 Insert boundary... 1 start Set interval text... 1 int+1 'word$' Insert boundary... 1 end ## if the start time of the next word does not equal end of current, mark end of current elsif start > 0 & end != startnextword Insert boundary... 1 start Set interval text... 1 int+1 'word$' Insert boundary... 1 end ## if end time of current word equals the start time of next, do not mark end of current elsif start > 0 & end = startnextword Insert boundary... 1 start Set interval text... 1 int+1 'word$' ## if start = 0, do not add a boundary otherwise praat will throw an error elsif start = 0 & end != startnextword Set interval text... 1 int 'phone$' Insert boundary... 1 end elsif start = 0 & end = startnextword Set interval text... 1 int 'word$' endif #pause endfor Save as text file... 'dir$'/'file2$'_word.TextGrid select LongSound 'file2$' plus TextGrid 'file2$' Remove
以下脚本将音素与单词层拼为一个标注文件:
# This script stacks two TextGrids to create one # Created 2 April 2015 E. Chodroff # Updated 8 Feb 2016 E. Chodroff dir$ = "/Volumes/MIXER6_cogsci/CzechNijmegen/alignment/tri1_ali_utf8" Create Strings as file list... czech 'dir$'/*.TextGrid Sort n = Get number of strings for i from 1 to n select Strings czech file$ = Get string... i base$ = file$ - ".TextGrid" Read from file... 'dir$'/'base$'.TextGrid Rename... file1 Read from file... 'dir$'/'base$'_word.TextGrid Rename... file2 select TextGrid file1 plus TextGrid file2 Merge Write to text file... 'dir$'/'base$'_final.TextGrid select TextGrid file1 plus TextGrid file2 plus TextGrid merged Remove i = i+1 endfor
编辑于 2021-11-