
在数字时代的浪潮中,大型语言模型如同智慧的巨人,以它们庞大的数据胃口和深邃的计算能力,支撑起智能助手、搜索引擎、内容推荐等众多现代技术奇迹。它们是我们这个时代的神话创造者,用算法编织着信息的宇宙。然而,这些巨人的思考过程却隐藏在层层迷雾之中,它们的决策宛如深渊中的低语,难以捉摸——这就是所谓的“黑匣子”问题。
Sam Altman, OpenAI 的联合创始人,曾经提到大型模型的这种“黑匣子”特性,他强调了理解模型决策过程的重要性。而 Meta 的首席 AI 科学家 Yann LeCun 也曾指出,我们需要更好的方法来解释和理解这些模型的内部机制。Google 的高级研究员 Jeff Dean 同样提到了评估这些模型的复杂性,以及确保它们的道德和社会可接受性。
这些来自行业巨头的声音,凸显了大型语言模型的评估和对齐问题所带来的挑战。我们如何确保这些模型不仅在技术上先进,而且在道德和社会标准上也是可接受的?我们如何打开这个“黑匣子”,一窥究竟,并确保它们的智能光芒照亮人类的未来,而不是迷失在未知的黑暗中?
Anthropic 的重大发现
Anthropic 的研究目标是深入探索 Claude 3 Sonnet 这样的大型语言模型,理解它们是如何通过一系列复杂的计算过程来处理信息的。研究者们试图回答一个核心问题:在这些模型的“心智”中,是否存在一些基本的构建块,即特征,它们能够响应特定的概念或模式?
正是在这样的背景下,Anthropic 的研究团队发布了一篇开创性的论文《Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet》,这篇论文最关键的技术发现是能够从大型语言模型 Claude 3 Sonnet 中提取出高度抽象、可解释的特征(features),并且这些特征具有多语言(multilingual)、多模态(multimodal)的特性,能够在具体和抽象的上下文中泛化。 这项研究展示了如何通过稀疏自编码器(sparse autoencoders) 来揭示和操纵这些特征,从而影响模型的行为。
与之前的研究成果相比,这项工作具有以下几个跨越性的进步:
大型模型的可解释性:以往的研究多集中在较小的模型上,而这篇论文成功地将可解释性技术应用于一个大型、复杂的生产级模型上,这在 AI 领域是一个重要的里程碑。
特征的系统性分析:研究者不仅提取了特征,还对它们进行了系统的分类和分析,揭示了特征之间的相关性和多样性,以及它们如何响应不同类型的输入。
特征操纵对行为的影响:通过实验,研究者展示了如何通过调整特定特征的激活强度来精确地引导和改变模型的输出,这在以往的研究中较难实现。
安全性相关特征的识别与调控:论文中提到了与安全性相关的特征,如代码安全漏洞、偏见、欺骗等,并展示了如何通过特征工程来调控这些安全性相关的行为,这对于构建更安全的 AI 系统至关重要。
特征的多语言和多模态响应:研究者发现的特征不仅限于单一语言或模态,而是能够跨语言和在文本与图像之间响应相同的概念,这增加了模型的通用性和适用性。
特征与神经元的对比:研究提供了特征与模型中单个神经元之间关系的见解,表明特征通常比单个神经元具有更高的可解释性,这对于理解模型的内部工作机制具有重要意义。
特征提取的扩展性:研究者使用了扩展法则(scaling laws)来指导稀疏自编码器的训练,这表明了特征提取方法的扩展性,为未来更大规模模型的特征提取提供了理论基础。
稀疏自编码器和扩展法则的应用
特征在 AI 模型中的作用就像人类大脑中的神经元一样,它们是模型理解和反应外部世界的基础。在 Claude 3 Sonnet 这样的大型语言模型中,特征的激活直接影响着模型的行为和输出。
稀疏自编码器(Sparse Autoencoders)并不是首次用于提取特征。自编码器作为一种神经网络架构,已经被研究和使用了几十年,而稀疏自编码器是自编码器的一种变体,它通过引入稀疏性约束来增强特征的可解释性。但是使用稀疏自编码器来提取大型语言模型中的特征,特别是在像 Claude 3 Sonnet 这样的复杂和大规模模型中,是一个技术上的创新。
Claude 3 Sonnet 是 Anthropic 公司推出的一款具有创新性的语言模型。它不仅能够理解和生成文本,还能够处理图像信息,这使得它在理解多模态数据方面具有独特的优势。Claude 3 Sonnet 的内部结构由多层神经网络组成,这些网络通过复杂的数学运算处理输入的信息。在这些网络中,每个神经元可以看作是一个简单的计算单元,它们相互连接,形成一个庞大的网络,可以处理和理解极其复杂的数据模式。
与其他语言模型相比,Claude 3 Sonnet 的一个显著特点是其多模态能力。这意味着它不仅能够处理文本数据,还能够理解和生成与图像相关的信息。这种能力使得 Claude 3 Sonnet 在处理包含丰富媒体内容的数据时更为出色。
以下是提取特征的步骤:
稀疏自编码器的应用:研究者们首先使用了稀疏自编码器这一强大的工具。自编码器由两部分组成:编码器和解码器。编码器负责将输入数据转换成一个内部表示,而解码器则尝试从这个内部表示重构输入数据。通过在自编码器中加入稀疏性约束,模型被迫学习到更加精炼和独立的特征表示。
优化和训练:接下来,研究者们对自编码器进行了训练,这一过程涉及到调整模型的参数,以最小化输入数据和重构数据之间的差异。通过这种方式,模型学习到了如何通过一组紧凑的特征来表示输入数据。
特征的识别:训练完成后,研究者们得到了一组特征,这些特征是模型内部表示的基础。每个特征都对应于数据中的特定模式或概念,例如,某个特征可能对应于识别文本中的“金门大桥”这一概念。
在论文《Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet》中,研究者使用扩展法则(scaling laws)来指导稀疏自编码器(SAE)的训练。 扩展法则是深度学习中的一个概念,它描述了模型性能如何随着模型大小(如参数数量)和训练数据量的增加而变化。以下是研究者如何应用这些法则的概述:
确定训练步骤和特征数量:研究者首先确定用于训练稀疏自编码器的训练步骤数和要学习的特征数量。这些参数的选择会影响模型的复杂度和学习能力。
分析计算资源:根据可用的计算资源,研究者分析了如何在训练步骤数和特征数量之间分配这些资源,以优化训练结果。
损失函数作为代理:由于缺乏评估字典学习质量的标准方法,研究者使用训练过程中的损失函数作为一个代理指标。损失函数结合了重建误差和特征激活上的 L1 正则化项。
优化损失函数:研究者通过调整训练步骤数和特征数量,寻找能够最小化损失函数的配置。这通常涉及到在不同的参数设置下进行广泛的实验。
应用扩展法则:扩展法则用于理解随着模型大小的增加,损失函数如何变化,以及如何有效地分配计算资源以获得最佳性能。研究者观察到,给定计算预算时,损失函数随计算量的增加而减少,呈现出幂律分布。
调整学习率:研究者还发现,随着计算预算的增加,最优学习率也会随之变化。他们使用扩展法则来推断不同计算预算下的最优学习率。
实验和迭代:研究者进行了一系列实验,调整稀疏自编码器的超参数,如特征数量、训练步骤和学习率,以找到最小化损失函数的最佳配置。
评估和选择:在实验过程中,研究者评估了不同配置下稀疏自编码器学习到的特征的质量和可解释性,并选择了最优的模型配置。
通过这种方法,Anthropic 的研究者能够系统地训练稀疏自编码器,并从中提取出高质量的、可解释的特征。这些特征不仅有助于理解大型语言模型的内部工作原理,还可以用于改进模型的性能和安全性。使用扩展法则来指导训练是一个创新的方法,它展示了如何在有限的计算资源下有效地扩展模型的规模和能力。
特征的可塑性 - 金门大桥
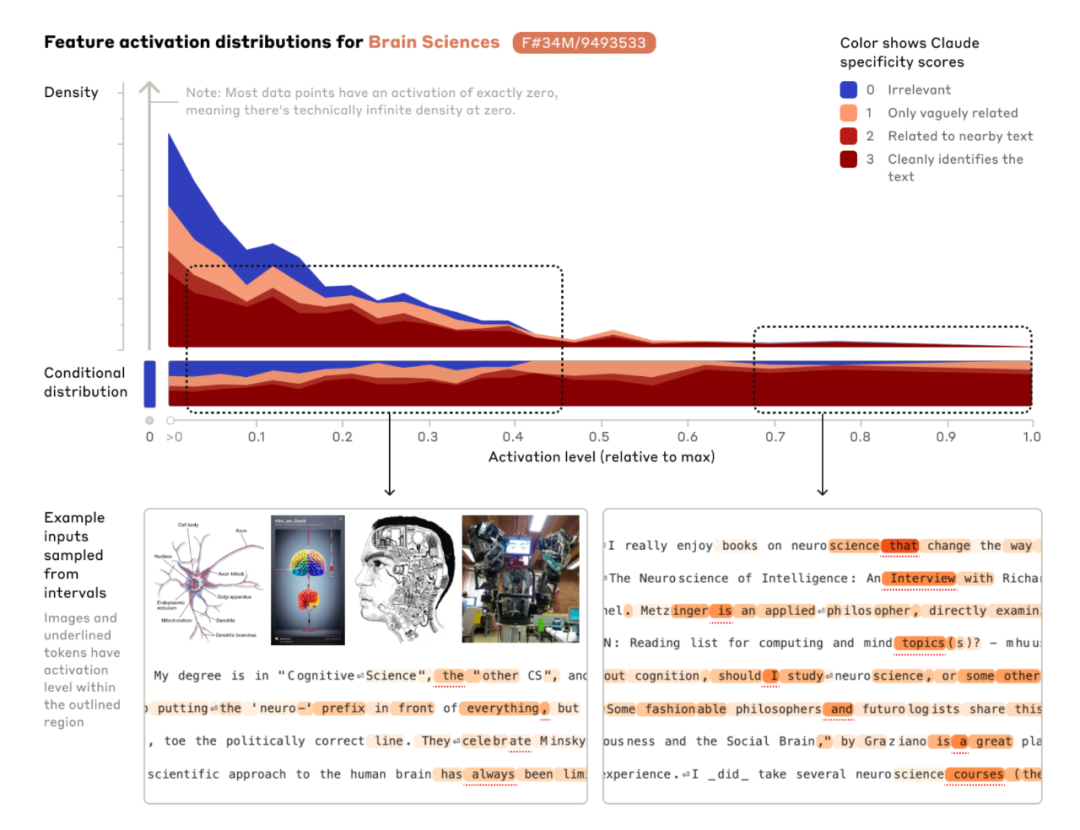
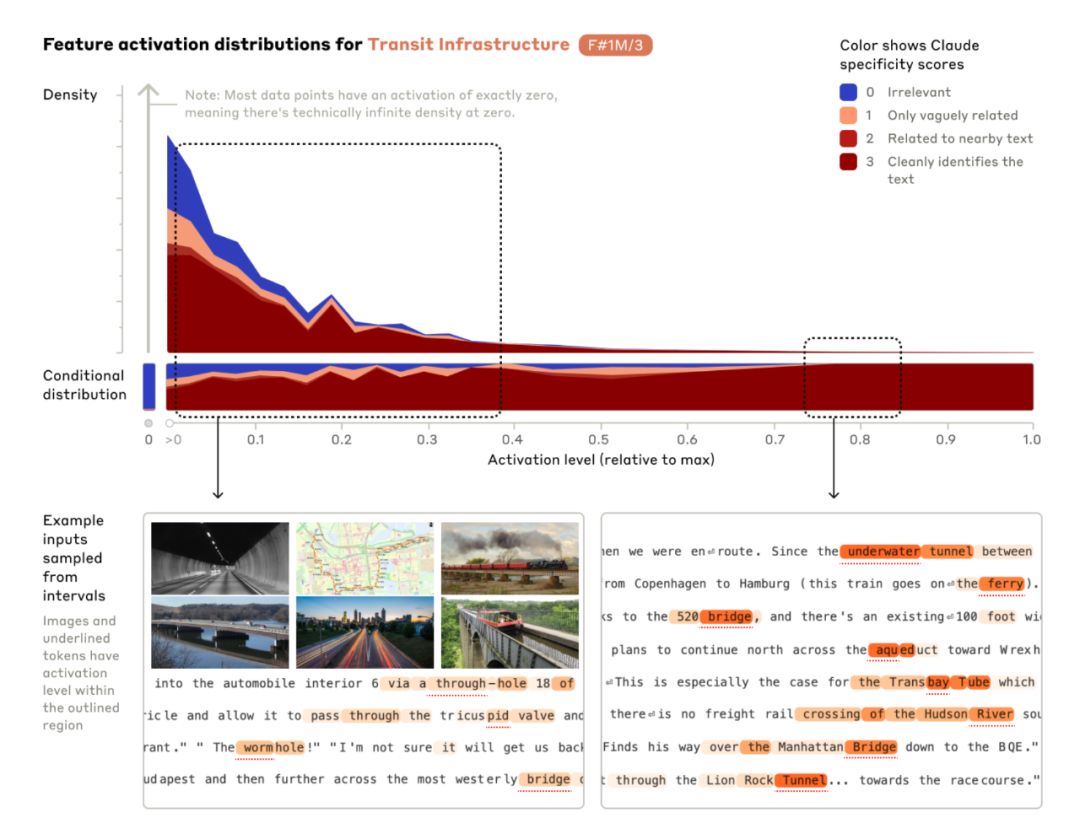
研究者发现,许多特征是跨语言和多模态的。这意味着,即使在不同的语言中,相同的概念也能触发相同的特征。
同样,这些特征也能够响应图像数据,表明模型能够在视觉和语言之间建立联系。特征之间也存在相互作用。 在某些情况下,一个特征的激活可能会影响其他特征的状态,从而产生复杂的交互效应。这种相互作用是模型理解和生成连贯、一致文本的基础。
特征在 AI 模型中的作用就像人类大脑中的神经元一样,它们是模型理解和反应外部世界的基础。 在 Claude 3 Sonnet 这样的大型语言模型中,特征的激活直接影响着模型的行为和输出。
当模型接收到输入数据时,与之相关的特征会被激活。这些特征的激活状态决定了模型如何解释输入,并生成相应的输出。例如,如果输入数据中包含与金门大桥相关的信息,那么与之对应的特征将被激活,模型可能会在输出中提及金门大桥,即使这个问题与金门大桥并无直接联系。

Claude 3 Sonnet 中的特征表现出极高的多样性和抽象性。这些特征不仅包括具体的名词或物体,如金门大桥,还包括抽象的概念、情感、行为模式等。这种多样性和抽象性是大型语言模型能够理解和生成复杂文本的关键。
在 Anthropic 的研究中,研究者通过实验展示了如何通过调整特定特征的激活强度来改变模型的行为。他们将这种调整称为“特征调整”或“特征转向”。通过人为地增强或减弱特定特征的激活,研究者能够引导模型产生特定的反应。
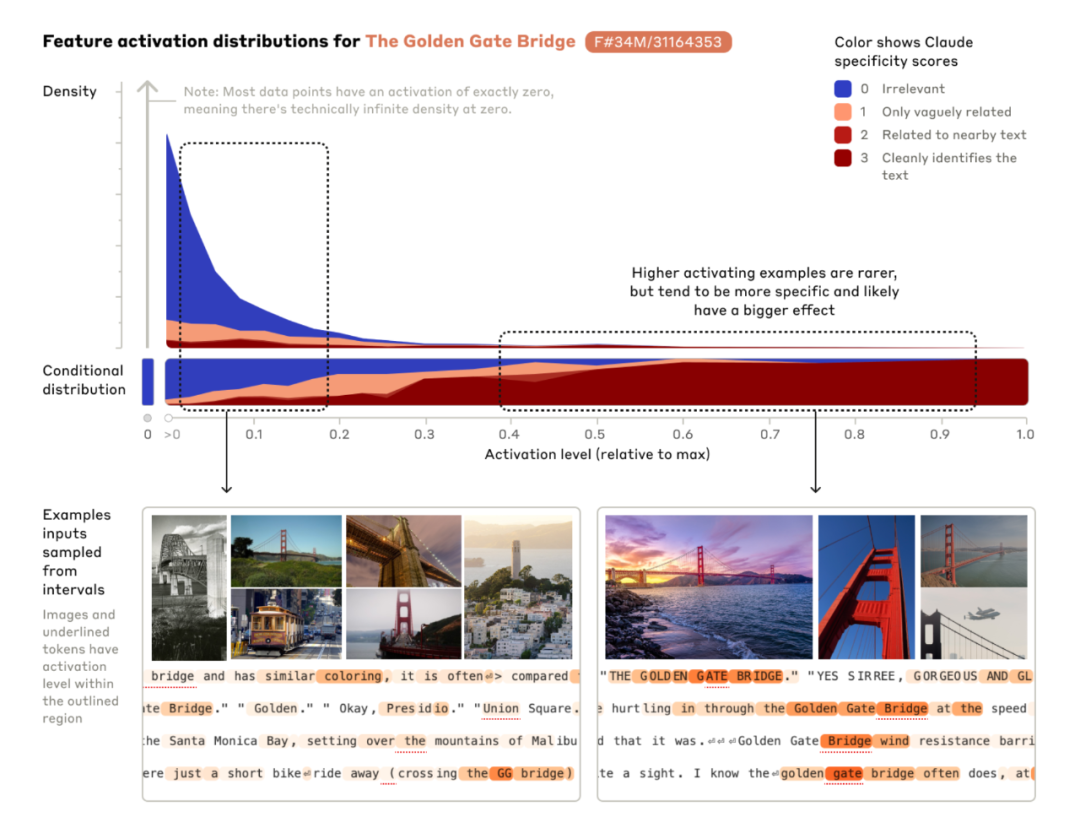

以“Golden Gate Claude”为例,研究者增强了与金门大桥相关的特征激活。结果,即使在看似不相关的查询中,模型的回复也开始聚焦于金门大桥。这表明,通过调整特征的激活,研究者能够在一定程度上控制模型的注意力和话题范围。
特征激活的模式与模型的行为紧密相关。特定的特征组合可以引导模型表现出特定的行为模式。例如,增强与“爱情”和“桥梁”相关的特征可能会使模型生成关于桥梁的爱情故事。特征的可塑性意味着我们可以通过训练和调整来塑造模型的行为。这为 AI 的定制化和优化提供了新的可能性,使模型能够更好地适应特定的应用场景和用户需求。
Anthropic 在 claude.ai 上提供了与金门大桥(Golden Gate Claude)的对话,只需要点击右侧的金门标志就可以进入研究展示。Anthropic 在官方博客中提到,如果你问这个金门 Claude 如何使用 10 美元,它会建议你用它开车穿过金门大桥并支付通行费,如果你让它写一个爱情故事,它会告诉你一辆汽车迫不及待地想在雾天穿越它心爱的大桥的故事。感兴趣的朋友不妨一试。
写在最后
在 Anthropic 的研究中,"Scaling Monosemanticity"特别指的是他们成功地将从小型模型中提取单义性特征的方法扩展到了大型、复杂的语言模型上,如 Claude 3 Sonnet。这项工作展示了即使在模型规模和复杂性增加的情况下,也能够提取出具有高度可解释性的特征,这对于提高 AI 系统的透明度和可控性具有重要意义。
"Scaling Monosemanticity"这个术语可以从两个方面来理解:首先是"monosemanticity"(单义性),其次是"scaling"(扩展或放大)。结合这两个概念,Scaling Monosemanticity 可以理解为:
扩大单义特征的提取:研究者致力于从大型语言模型中提取出更多的单义性特征,即那些能够明确对应于特定概念的特征。
提高模型的可解释性:通过扩展单义特征的提取,研究者希望提高模型的可解释性,使得模型的行为更加透明,更容易被人类理解和信任。
应对更大规模模型的挑战:随着模型规模的增长,保持或提高特征的单义性变得更加困难。"Scaling Monosemanticity"强调了在模型规模扩大的同时,如何保持或提升特征的清晰度和一致性。
"Scaling Monosemanticity"作为论文标题,简洁而精确地捕捉了研究的精髓:在扩展模型规模的同时,提取出有助于提高模型可解释性的单义性特征。这不仅体现了研究的创新性,也突出了其在 AI 领域中的重大意义。
随着 Anthropic 研究团队在《Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet》中所展示的突破性成果,我们站在了人工智能可解释性领域的新起点。这项研究不仅为我们提供了洞察大型语言模型内部工作机制的新工具,也为未来的 AI 发展开辟了新的可能性。
参考链接:
https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
https://www.anthropic.com/news/golden-gate-claude
声明:本网站所提供的信息仅供参考之用,并不代表本网站赞同其观点,也不代表本网站对其真实性负责。
 京公网安备11011102001052号
京公网安备11011102001052号 
